NVIDIA ChatRTX – Rewolucja w lokalnej AI? Recenzja, funkcje i wymagania
NVIDIA ChatRTX to narzędzie, które zaskakuje możliwościami lokalnej sztucznej inteligencji. W dobie rosnącej popularności chatbotów opartych na chmurze, NVIDIA postawiła na alternatywę działającą lokalnie na Twoim komputerze, bez potrzeby łączenia się z serwerami zewnętrznymi. Czy to krok w stronę większej prywatności i kontroli? Sprawdzamy!
Co to jest NVIDIA ChatRTX?
ChatRTX to aplikacja demonstracyjna od NVIDII, która wykorzystuje lokalne modele językowe LLM (Large Language Models), takie jak Mistral lub Llama 2, aby umożliwić interakcję z chatbotem AI bez dostępu do Internetu. Narzędzie potrafi przeszukiwać dokumenty, odpowiadać na pytania w czasie rzeczywistym i działa z wykorzystaniem akceleracji GPU (RTX).
Najważniejsze funkcje ChatRTX
- Lokalne LLM – brak połączenia z chmurą, pełna prywatność.
- Obsługa dokumentów użytkownika – możesz analizować własne pliki PDF, Word, TXT i inne.
- Akceleracja przez RTX – wykorzystuje moc GPU do szybszego działania AI.
- Wsparcie dla modeli open-source – możliwość zmiany lub załadowania własnych LLM.
- Interfejs przeglądarkowy (lokalny) – działa przez localhost w przeglądarce.
Wymagania sprzętowe
Aby uruchomić ChatRTX, potrzebujesz:
- GPU NVIDIA RTX (minimum seria 30XX)
- System operacyjny Windows 11
- Sterowniki NVIDIA Studio (551.22 lub nowsze)
- RAM: min. 16 GB (zalecane 32 GB)
- Wolne miejsce na dysku: ~50 GB na modele i dane
Jak działa ChatRTX w praktyce?
Instalacja jest prosta – pobieramy paczkę instalacyjną ze strony NVIDIA, uruchamiamy i po kilku minutach jesteśmy gotowi do rozmowy z lokalnym chatbotem. Domyślnie działa z modelem Mistral, ale można wgrać inne modele (np. Llama 2, Gemma).
ChatRTX błyskawicznie odpowiada na pytania, radzi sobie z analizą lokalnych dokumentów (np. przeszukuje instrukcje PDF, raporty, umowy), a dzięki wykorzystaniu GPU odpowiedzi są generowane szybko i płynnie.
Zalety i wady
✅ Zalety:
- Pełna prywatność – dane nie wychodzą poza Twój komputer.
- Szybkość – dzięki GPU odpowiedzi są generowane niemal natychmiastowo.
- Możliwość pracy offline.
- Łatwa integracja z własnymi dokumentami.
❌ Wady:
- Wysokie wymagania sprzętowe (tylko dla posiadaczy RTX i Windows 11).
- Interfejs użytkownika jest prosty, ale nadal w fazie demo
- Modele zajmują sporo miejsca na dysku.
- Brak wersji na Linux lub macOS.
Czy warto?
Jeśli masz komputer z kartą RTX i pracujesz z poufnymi dokumentami – zdecydowanie warto. ChatRTX to jedno z pierwszych narzędzi pokazujących realną moc lokalnych LLM w środowisku użytkownika końcowego. Sprawdza się świetnie jako asystent do przeszukiwania dokumentów, pomocy technicznej czy codziennej pracy bez ryzyka naruszenia prywatności.
Jak zainstalować Nvidia ChatRTX?
⚙️ Krok 0: Upewnij się, że masz właściwy sterownik
- Wejdź do GeForce Experience lub Panelu sterowania NVIDIA.
- Sprawdź wersję sterownika – powinna być co najmniej 551.22 (Studio).
- Jeśli nie – pobierz ze strony NVIDIA:
👉 https://www.nvidia.com/Download/index.aspx
📥 Krok 1: Pobierz instalator ChatRTX
- Przejdź na oficjalną stronę NVIDIA:
👉 Build a Custom LLM with ChatRTX | NVIDIA - Kliknij „Download ChatRTX” i zapisz plik instalacyjny (ok. 35 GB z modelami).
💽 Krok 2: Zainstaluj ChatRTX
- Uruchom pobrany instalator EXE.
- Wybierz katalog docelowy (potrzebne ~50 GB wolnego miejsca).
- Instalator pobierze wymagane komponenty, modele AI i skonfiguruje środowisko.
💡 Uwaga: instalacja może potrwać kilka-kilkanaście minut – zależnie od szybkości dysku i łącza internetowego.
▶️ Krok 4: Uruchom ChatRTX
- Po zakończeniu instalacji otwórz ChatRTX Launcher z menu Start.
- ChatRTX uruchomi się w aplikacji.
- Wybierz model (np. Mistral lub Llama 2) i rozpoczynamy zabawę
📄 Krok 5 (opcjonalny): Załaduj własne dokumenty
- Wskaż folder z danymi w trybie „Chat with your data”
- AI będzie w stanie analizować i odpowiadać na pytania dotyczące tych dokumentów.
💡 Dodatkowe wskazówki
- Możesz dostosować modele lub pliki konfiguracyjne – są one w folderze instalacyjnym.
- Obsługiwane modele to m.in. Mistral, Llama 2, Gemma, wszystkie działające lokalnie.
- Nie potrzebujesz połączenia z Internetem po zakończonej instalacji (offline-ready).
Test w środowisku: i5-12600K + 32 GB RAM + RTX 3070
NVIDIA ChatRTX to nowy projekt umożliwiający uruchomienie lokalnego chatbota AI bez potrzeby korzystania z chmury czy połączenia z internetem. Bazuje na modelach open-source (jak LLaMA 2, Mistral czy Gemma) i wykorzystuje moc GPU RTX do szybkiego przetwarzania języka naturalnego. Sprawdziłem, jak działa na realnym sprzęcie.
🖥️ Moje środowisko testowe
| Komponent | Konfiguracja |
|---|---|
| Procesor | Intel Core i5-12600K (12. gen, 10 rdzeni) |
| RAM | 32 GB DDR4 |
| GPU | NVIDIA GeForce RTX 3070 8 GB |
| System | Windows 11 Pro, 64-bit |
| Sterownik NVIDIA | Studio Driver v551.86 |
| Dysk SSD NVMe | 1 TB, wolne ok. 300 GB |
🚀 Pierwsze uruchomienie
Po zakończeniu instalacji uruchamiamy ChatRTX – aplikacje z menu start
🧠 1. Chat with AI Model
To klasyczna interakcja z dużym modelem językowym (LLM), który działa całkowicie lokalnie – bez połączenia z internetem.
Na dzień pisania recenzji dostępny jest:
- Mistral 7B (int4) – zoptymalizowany, szybki model do rozmów ogólnych, pytań technicznych, parafrazowania tekstu czy pisania kodu.
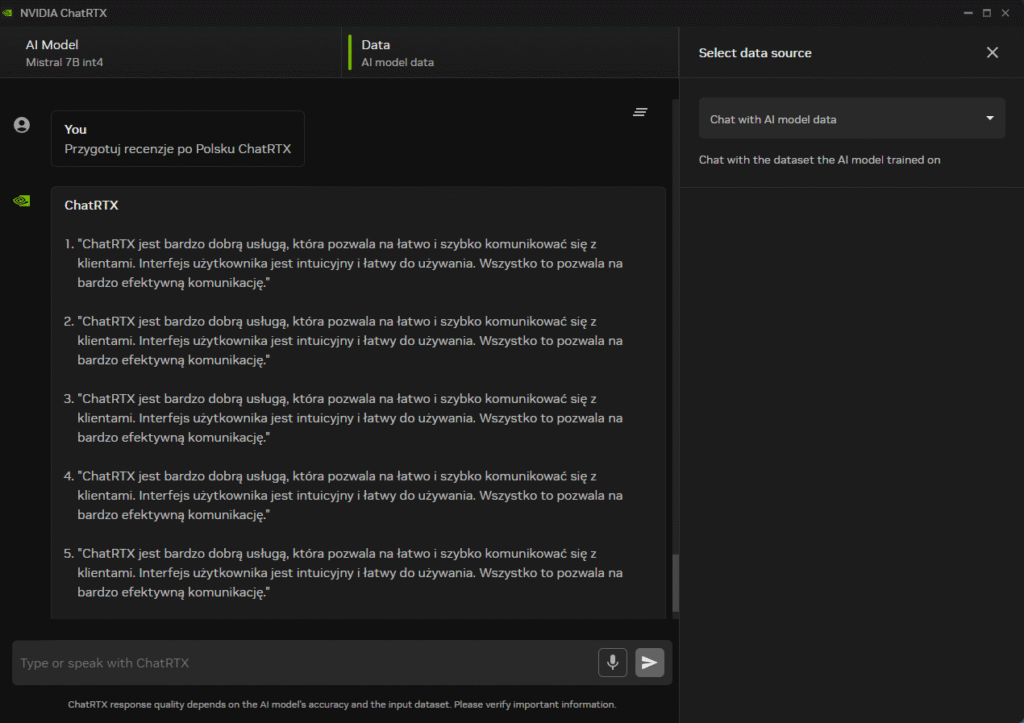
Model Mistral działa bardzo sprawnie – na moim zestawie (RTX 3070) odpowiedzi generowane są z prędkością około 1 tokena na milisekundę. Oznacza to, że większość odpowiedzi pojawia się natychmiastowo, bez zauważalnych opóźnień.
Model trzeba uczyć jak małe dziecko
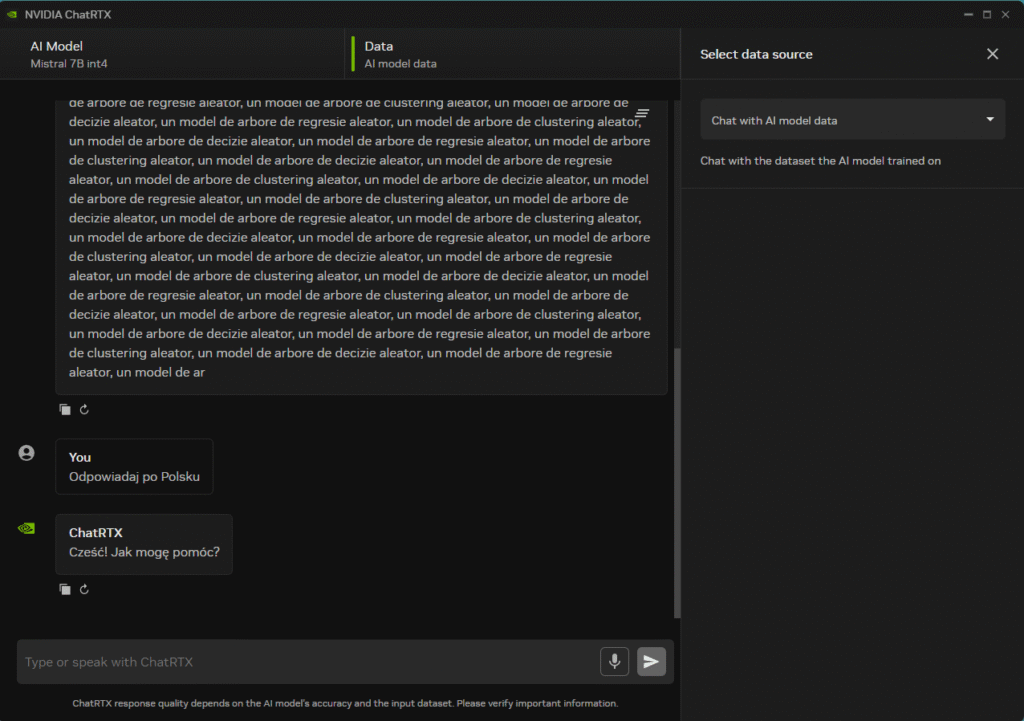
📂 2. Chat with Your Data
Ten tryb pozwala na zadawanie pytań na podstawie własnych dokumentów.
Wystarczy wskazać folder w którym są pliki w formacie:
- DOCX
- TXT
- CSV
Po wczytaniu dokumentów można zadawać pytania typu:
„Ile kosztował projekt X?”
„Podsumuj dokument w 3 punktach.”
„Które rozdziały zawierają dane finansowe?”
Wszystko przetwarzane jest lokalnie – dane nie są wysyłane do chmury, co jest ogromnym plusem dla użytkowników ceniących prywatność i bezpieczeństwo.
⚠️ Podsumowanie – Potrzeba dopracowania
Choć NVIDIA ChatRTX to imponujący krok w stronę lokalnej sztucznej inteligencji, na obecnym etapie aplikacja wymaga jeszcze dopracowania. Podczas testów zauważyłem, że:
- Model potrafi niespodziewanie zmieniać język odpowiedzi w trakcie jednej rozmowy – nawet jeśli początkowo komunikacja przebiegała po polsku, nagle pojawiają się fragmenty po angielsku lub w niezrozumiałej formie.
- ChatRTX często nie rozumie prostych pytań, które dla ChatGPT (np. GPT-4 lub nawet GPT-3.5) są banalne i generuje odpowiedzi nie na temat lub w formie „halucynacji”.
To pokazuje, że choć lokalna inferencja z pomocą GPU działa technicznie bardzo dobrze, to same modele i ich integracja z interfejsem wymagają dalszego rozwoju, szczególnie w kontekście wielojęzyczności i zgodności z intencją użytkownika.
W obecnej wersji ChatRTX to ciekawostka dla entuzjastów i testerów, ale nie zastąpi jeszcze w pełni sprawdzonego chatbota w chmurze.
Bonus 🙂